Operations Enterprise
This feature is in alpha and certain aspects will change
We're very excited for people to use this feature. However, please note that changes in the API, behaviour and security will evolve. The feature is suitable to use in controlled testing environments.
As platform engineer you could need to have a finer understanding on the underlying logic for Explorer. The following options are available to you to operate and troubleshoot it.
Debug Access Rules
It is a debugging tool to make visible explorer authorization logic. You could find it as tab Access Rules alongside
the Query tab.
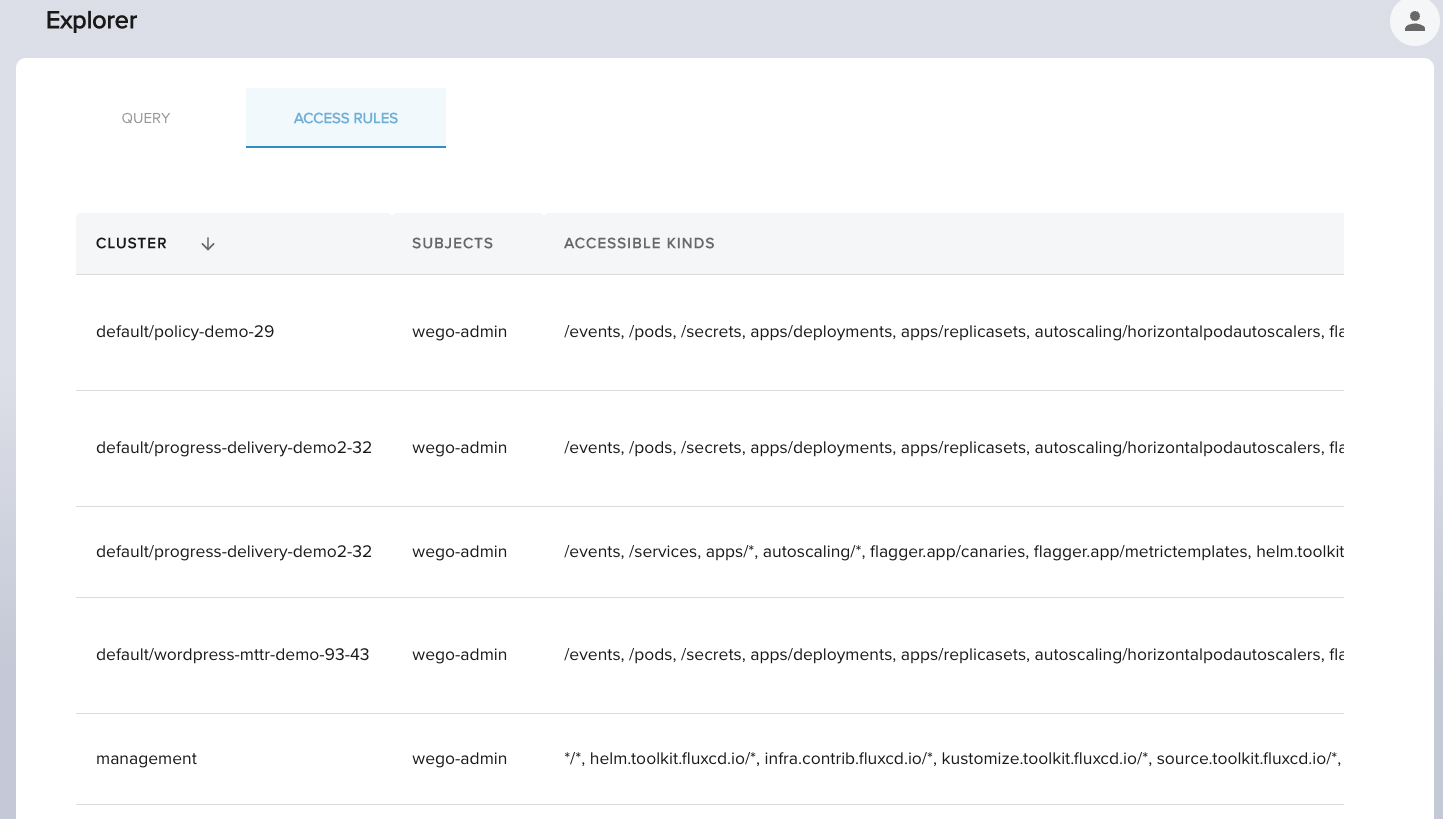
You could discover by Cluster and Subject the Kinds it is allowed to read. These are the rules that
will be the source of truth doing authorization when a user does a query.
Monitoring
Explorer provides the following telemetry to use for operations.
Metrics
Explorer exports Prometheus metrics.
Configuration happens during releasing as shown below.
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: weave-gitops-enterprise
namespace: flux-system
spec:
values:
#### Metrics - Prometheus metrics configuration
metrics:
# Enables metrics generation and prometheus endpoint
enabled: false
service:
# -- Port to start the metrics exporter on
port: 8080
# -- Annotations to set on the service
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: "/metrics"
prometheus.io/port: "{{ .Values.metrics.service.port }}"
Querying
Based on go-http-metrics, the following metrics are generated.
Request Duration: histogram with the latency of the HTTP requests.
http_request_duration_seconds_bucket{handler="/v1/query",method="POST",le="0.05"} 0
http_request_duration_seconds_sum{handler="/v1/query",method="POST"} 10.088081923
http_request_duration_seconds_count{handler="/v1/query",method="POST"} 51
Response Size: histogram with the size of the HTTP responses in bytes
http_response_size_bytes_bucket{handler="/v1/query",method="POST",le="0.05"} 10
http_response_size_bytes_sum{handler="/v1/query",method="POST"} 120
http_response_size_bytes_count{handler="/v1/query",method="POST"} 10
Request In Flight: gauge with the number of inflight requests being handled at the same time.
http_requests_inflight{handler="/v1/query"} 0
Collecting
The following metrics are available to monitor the collecting path
Cluster Watcher Status
The metric collector_cluster_watcher provides the number of the cluster watchers it the following state:
- Starting: a cluster watcher is starting at the back of detecting that a new cluster has been registered.
- Started: cluster watcher has been started and collecting events from the remote cluster. This is the stable state.
- Stopping: a cluster has been deregistered so its cluster watcher is no longer required. In the process of stopping it.
- Failed: a cluster watcher has failed during the creation or starting process and cannot collect events from the remote clusters. This is the unstable state.
collector_cluster_watcher{status="Starting"} 0
collector_cluster_watcher{status="Started"} 1
collector_cluster_watcher{status="Stopping"} 0
collector_cluster_watcher{status="Failed"} 0
A sum on collector_cluster_watcher gives the total number of cluster watchers that should be equal to the number of clusters
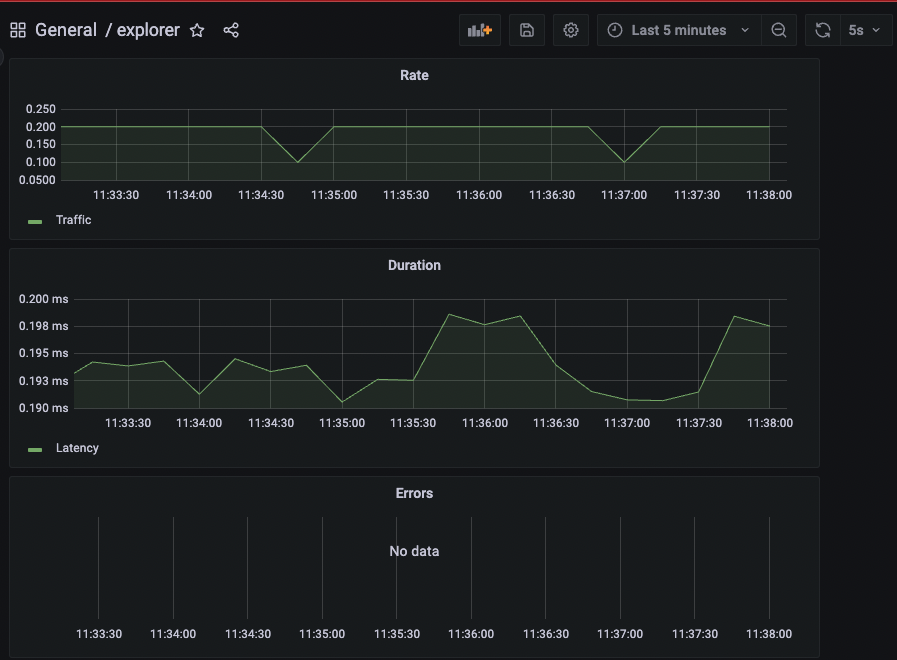
Dashboard
You could leverage this grafana dashboard in Grafana to monitor its golden signals